
Oder wie funktioniert Alexa SEO
Mittlerweile gibt es über 50000 Skills (Erweiterungen) für Amazons Sprachassistentin Alexa, aber nur der kleinste Teil davon ist auch in deutscher Sprache verfügbar. Aktuell sehe ich hier den Markt so ähnlich wie Mitte der 90er Jahre im letzten Jahrhundert, wo es einen "Run" auf die Internetdomains gab. Heute sind es die neuen Domains die "Invocation Names" und "Uterrances".
Wenn wir unseren Kunden die Notwendigkeit eines eigenen Skills erklären und die aktuelle Funktionalität erklären, kommen schnell Einwende, dass man sich ja den Skill-Namen immer merken muss, und dass dies sehr unwahrscheinlich ist, dass die Leute das machen werden. Diesen Einwand könnte ich gleich auf mehrere Art zerpflücken, weil es schon auch mehreren Ebenen falsch ist.
- Ja, ein Skill-Name ist zuerst umständlich sich zu merken. Er ist aber auch zugleich ein Branding-Instrument und jeder Marketer, Unternehmer sollte bestrebt sein eine eigene Marke aufzubauen.
- Der Umstand, dass ein Skill-Name für den Aufruf erforderlich ist, ist in Deutschland nur eine Übergangslösung. In den USA gibt es schon Skills die einen CanFulfillIntentRequest erkennen.
Was ist ein CanFulfillIntentRequest?
Mit der CanFulfillIntentRequest Funktion kann ein Skill Alexa mitteilen wäche Anfragen der Skill beantworten kann. Alexa kombiniert diese Informationen mit einem Machine-Learning-Modell, um den richtigen Skill auszuwählen, wenn ein Kunde eine Anfrage ohne Aufrufnamen abruft. Daher finden Kunden die richtigen Skills schneller und verwenden dabei die Suchbegriffe, die sie am natürlichsten sagen. Wenn ein Kunde mit Alexa spricht, ohne eine Skill mit dem Namen aufzurufen, wählt Alexa den besten Skill, der auf der Grundlage des Machine-Learning-Modells aufgerufen werden kann.
Der CanFulfillIntentRequest ermöglicht es Alexa, das Modell des maschinellen Lernens um Informationen zu erweitern, die von einem Skill bereitgestellt wird. Mit CanFulfillIntentRequest kann Alexa mehrere Skills abfragen, ob sie die Anforderung erfüllen können, wenn die Kundenabsicht und die Slot-Werte berücksichtigt werden. Wenn ein Kunde beispielsweise fragt: "Alexa, wo kann ich am besten Surfen heute in der Nähe von Santa Barbara?", Kann Alexa den CanFulfillIntentRequest verwenden, um die Surf-Skills zu fragen, ob sie die Anforderung verstehen und erfüllen können. Ein Surf-Skill mit einer Datenbank kalifornischer Strände kann die Anforderung sowohl verstehen als auch erfüllen, während eine Datenbank mit hawaiianischen Stränden sie möglicherweise nur verstehen kann. Basierend auf diesen Antworten würde Alexa den Skill mit der Datenbank der Strände von Kalifornien für den Kunden aufrufen.
Im Grunde ist dieser CanFullfillIntentRequest so etwas wie das Meta-Keywords Tag für Webseiten, nur dass man hier keine Keywords hinterlegt, sondern Suchsphrasen. Diese müssen dann aber auch erfüllt werden. Und es gibt noch weitere Prüfungsinstanzen, die Alexa heranzieht um einen bestimmten Skill aufzurufen.
Die skalierbare neuronale Architektur hinter Alexas Fähigkeit, Skills auszuwählen
Mittlerweile nutzen vier von fünf Alexa-Nutzer eine Fremdfunktionalität (Skill). Amazon sucht immer nach Möglichkeiten, den Nutzern die Suche nach Skills zu erleichtern.
Die Suche nach den relevantesten Skill im Umgang mit einer Nutzeräußerung ist aus zwei Gründen eine wissenschaftliche und technische Herausforderung:
- Die Vielzahl potenzieller Skills macht die Aufgabe schwierig. Im Gegensatz zu herkömmlichen digitalen Assistenten, die zwischen 10 und 20 integrierte Domänen haben, muss Alexa durch mehr als 50.000 navigieren. Und diese Zahl steigt wöchentlich.
- Im Gegensatz zu herkömmlichen integrierten Domänen, die sorgfältig entwickelt wurden, um in ihren Aufgabengebiet zu bleiben, können Alexa-Skills überlappende Funktionen abdecken. Zum Beispiel gibt es Dutzende von Skills, die auf Äußerungen im Zusammenhang mit Rezepten reagieren können.
Das Problem hier ist im Wesentlichen ein weitreichendes Problem bei der Domänenklassifizierung über Zehntausende von Skills hinweg. Dies ist eine der vielen aufregenden Herausforderungen, die Alexa-Wissenschaftler und -Ingenieure mit Deep-Learning-Technologien angehen, so dass die Interaktion mit Alexa für Kunden natürlicher und reibungsloser sein kann.
._CB476364052_.png?t=true)
Shortlister tiefe neurale Architektur
Alexa verwendet einen zweistufigen, skalierbaren und effizienten neuronalen Shortlisting-Reranking-Ansatz, um den relevantesten Skill für eine gegebene Äußerung (Uterrance ) zu finden. Dieser Abschnitt beschreibt den ersten dieser beiden Schritte, der auf einem neuronalen Modell beruht, das Amazon Shortlister nennt. Der Shortlister ist eine skalierbare und effiziente Architektur mit einem gemeinsamen Encoder, einem personalisierten Skill-Aufmerksamkeitsmechanismus und Skill-spezifischen Klassifizierungsnetzwerken. Amazon skizziert diese Architektur in ihrem Artikel „Effiziente neuronale Domänenklassifizierung mit personalisierter Aufmerksamkeit“.
Das gemeinsam genutzte Encoder-Netzwerk ist hierarchisch aufgebaut: Seine unteren Schichten sind auf Zeichen und Orthographie empfindlich und lernen, jedes Wort anhand der Zeichenstruktur oder -form darzustellen. Seine mittleren Schichten sind wortbasiert, und mit den Ausgaben der unteren Schichten lernen sie, eine gesamte Äußerung darzustellen. Der Skill-Aufmerksamkeitsmechanismus ist ein separates Netzwerk, das für jeden Benutzer personalisiert ist. Es berechnet einen Zusammenfassungsvektor, der beschreibt, welche Skills in einem bestimmten Benutzerprofil aktiviert sind und wie relevant sie für die Äußerungsdarstellung sind. Sowohl der Äußerungsrepräsentationsvektor als auch der personalisierte Skill-Zusammenfassungsvektor speisen in eine Batterie von Skill-spezifischen Klassifizierungsnetzwerken ein, ein Netzwerk für jeden Skill.
Während des Trainings wird das System als Ganzes auf der Grundlage der Ergebnisse der Kompetenzklassifizierungsnetze bewertet. Infolgedessen lernt der gemeinsam genutzte Encoder Äußerungen auf eine Weise darzustellen, die für die Klassifizierung von Skills nützlich ist, und der personalisierte Skill-Aufmerksamkeitsmechanismus lernt, sich auf die relevantesten Skills zu konzentrieren.
In dem Amazon Experimenten hat das System mit dem Skill-Aufmerksamkeitsmechanismus eine wesentlich bessere Leistung gezeigt als mit einem Vektor, der benutzeraktivierte Skills darstellt, mit einem Bit für jeden Skill. Er hat jedoch bessere Ergebnisse erzielt, wenn er sowohl im Tandem als auch im isolierten Einsatz verwendet wurde.
Während Amazon seine Architektur für Zehntausende von Skills skalierbar macht, halten sie sich an die praktischen Einschränkungen, indem sie sich auf die Minimierung des Speicherbedarfs und der Laufzeitlatenz konzentrieren, die für die Leistung von Produktionssystemen wie Alexa von großer Bedeutung sind. Derzeit benötigen Inferenzen 50 MB Speicher und die p99-Latenzzeit beträgt 15 Millisekunden. Darüber hinaus ist Amazons Architektur so konzipiert, dass neue Skills, die zwischen den gesamten Umschulungszyklen verfügbar werden, effizient berücksichtigt werden.
Was ist der HypRank?
Dieses Thema dürfte vor allem viele Google SEOs interessieren. Neben den CanFullfillIntentRequest versucht Alexa über den HypRank einen passenden Skill für eine bestimmte Nutzeräußerung zu finden. Es ist eine Art Klassifizierungsmodell von Skills, ähnlich einem Suchmaschinenalgorithmus.
Der weiter oben genannte Shortlisting-Schritt verwendet ein skalierbares neuronales Modell, um effizient die optimalen (k-besten) Kandidaten-Skills für die Handhabung einer bestimmten Äußerung zu finden. Der Schritt des erneuten Einstufens verwendet umfangreiche kontextsensitive Signale, um die relevantesten dieser Skills zu finden. Amazon verwendet den Begriff „Re-Ranking“, da Amazon den anfänglichen Vertrauensfaktor, der durch den Shortlisting-Schritt bereitgestellt wird, verbessert.
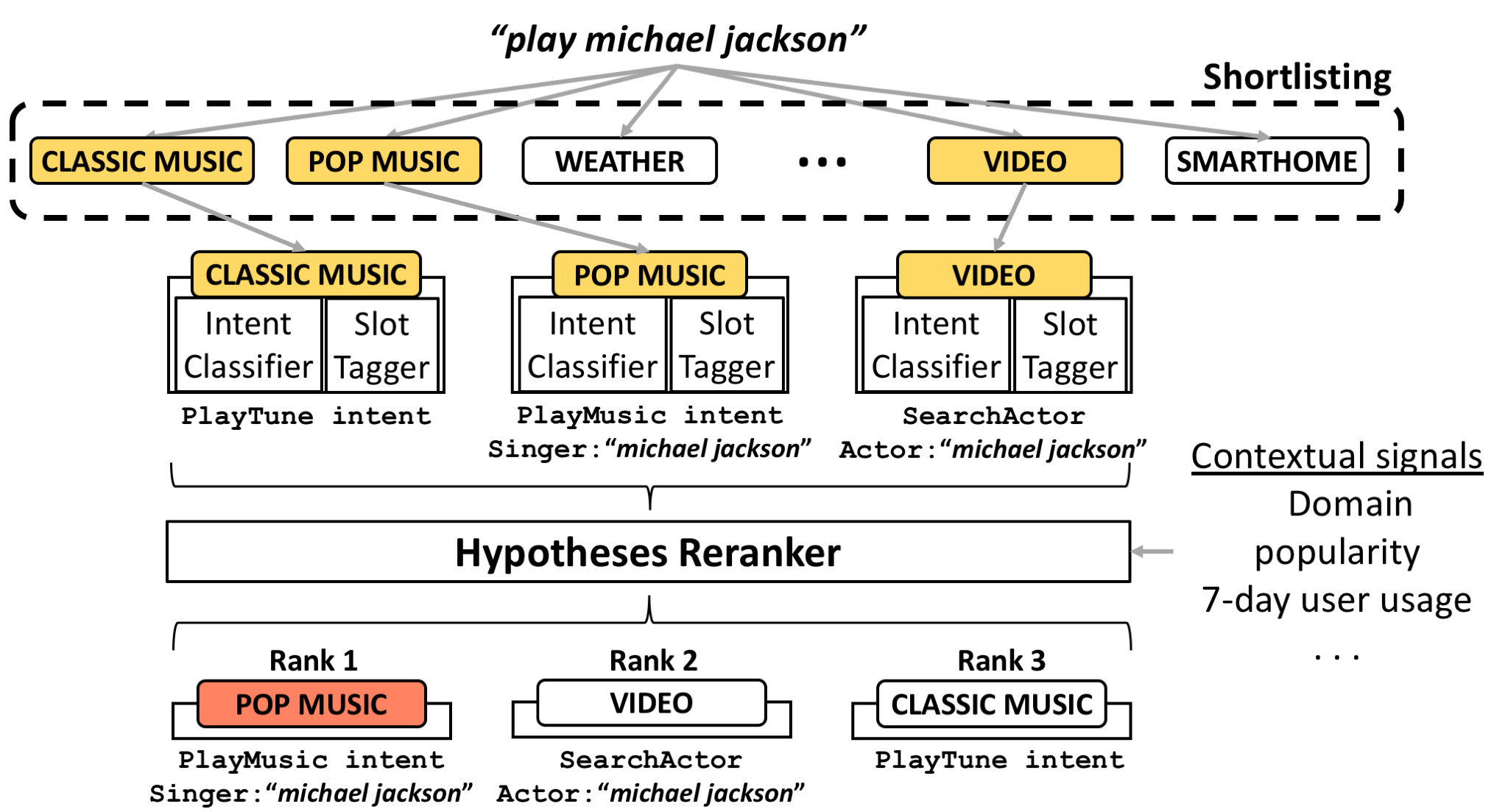
Ein High-Level-Flow des zweischrittigen Shortlisting-Reranking-Ansatzes
Die Schwierigkeiten bei der Umsetzung
Das Problem hier ist im Wesentlichen ein Domänenklassifizierungsproblem gegenüber den k-besten Kandidaten-Skills, die vom Shortlisting-System zurückgegeben werden. Das Ziel von Shortlister ist es, einen hohen Rückruf zu erreichen - möglichst viele relevante Skills zu identifizieren - mit maximaler Effizienz. Auf der anderen Seite besteht das Ziel des Reranking-Netzwerks, HypRank, darin, kontextabhängige Signale zu verwenden, um eine hohe Präzision zu erreichen - um die relevantesten Skills auszuwählen. Die Gestaltung von HypRank bringt eigene Herausforderungen mit sich:
• Hypothesendarstellung: Es müssen verfügbare kontextsensitive Signale verwendet werden, um eine effektive Hypothesendarstellung für jeden Skill in der k-best-Liste zu erstellen.
• Hypothesenübergreifende Feature-Repräsentation: Features müssen effizient und automatisch mit den Skills anderer Bewerber in der k-best-Liste verglichen werden, z.
• Verallgemeinerung: Es muss sprachunabhängig sein; und
• Robustheit: Der HypRank muss in der Lage sein, Änderungen zu berücksichtigen, wie zum Beispiel unabhängige Änderungen an Shortlister oder an Modellen zum Verständnis natürlicher Sprache, die eine skillspezifische semantische Interpretation von Äußerungen ermöglichen.

Neuronale Hypothesen Reranker-Modellarchitektur
Der HypRank besteht aus zwei Komponenten:
1. Darstellung der Hypothese für jeden Skill; und
2. ein bidirektionales Langzeitgedächtnis (Bi-LSTM) -Modell zum Neueinstellen einer Liste von Hypothesen.
Für jeden Skill in der k-best-Liste bildet Amazon eine Hypothese, die auf zusätzlichen semantischen und kontextuellen Signalen basiert. Zum Beispiel führt Amazon eine semantische Analyse der Intent-Slots eines Skills durch. Wenn ein Benutzer „Michael Jackson spielen“ sagt, kann der Pop-Musik-Skill die Absicht PlayMusic ableiten, während der Klassik-Musik-Skill die Absicht PlayTune ableiten kann. Die Vertrauensbewertungen, die die Skills ihren Schlussfolgerungen zuordnen, könnten jedoch für die Neubewertung der Skill hilfreich sein. Der Hypothesengenerator wird ständig aktualisiert, um Signale neu zu gewichten und neue Funktionen und Änderungen der Nutzungsmuster zu berücksichtigen.
HypRank ist aufgrund seines Listen-Ranking-Ansatzes, der eine Bi-LSTM-Schicht verwendet, einzigartig. LSTM-Modelle sind bei der Verarbeitung in natürlicher Sprache üblich, da sie die Reihenfolge der empfangenen Daten berücksichtigen: Wenn Sie versuchen, das sechste Wort in einer Äußerung zu verstehen, ist es hilfreich zu wissen, was die vorherigen fünf waren. Bidirektionale LSTM-Modelle berücksichtigen Datensequenzen sowohl vorwärts als auch rückwärts.
Durch die Nutzung der Bi-LSTM-Schicht kann HypRank eine vollständige Liste der Skillhypothesen auswerten, bevor für jede Hypothese eine Rangfolge für die Neubewertung vergeben wird. Dies unterscheidet sich von punktweisen Ansätzen, die jede Hypothese isoliert betrachten, oder paarweisen Ansätzen, die Paare von Hypothesen in einer Reihe von turnierartigen Wettbewerben betrachten.
Während Ansätze zur Neueinstufung in der Vergangenheit auf manuell erstellten Crosshypothese-Features beruhten, verwendet Amazons Ansatz die Bi-LSTM-Schicht, um geeignete Crosshypothese-Features automatisch zu lernen und zu kodieren, um die Rangfolge neu zu bestimmen. Der kodierte Kreuzhypothesenvektor durchläuft dann ein herkömmliches Vorwärtskopplungsnetzwerk, das die endgültige Bewertung für jede Hypothese bestimmt.
HypRank ist in Bezug auf Sprache und Gebietsschema agnostisch. Die Kontextinformationen, die zur Bildung einer Hypothese verwendet werden, sind unabhängig davon, ob die gesprochene Sprache Englisch oder Französisch ist und ob die Ländereinstellung die USA oder Frankreich ist. Amazon arbeiten kontinuierlich daran, HypRank so verallgemeinerbar wie möglich zu gestalten und auch gegenüber Änderungen der Upstream-Signale so robust wie möglich zu sein.
Fazit
Die oben beschrieben Verfahren finden aktuell nur in der USA statt. Doch es ist zu erwarten, das Amazon diese Verfahrensweise auch bald auf alle anderen Sprachen und Länder ausweiten wird. Von daher ist ein eigener Skill, ein erster guter Schritt in einem Sprachgestützen Internet Fuß zu fassen. Jetzt werden gerade die Claims abgesteckt und aktuell ist noch einfach bestimmte Entitäten für sich zu gewinnen. Grundlage für die bessere Auffindbarkeit dürfte immer noch der richtige Skillname sein und die im Skill hinterlegten Äußerungen, sowie die Beschreibung im Skill Store die zusätzlich auch mit Keywords angereichert wird. Auch Signale wie positive Bewertungen und die Anzahl der Nutzer eines Skills dürften entscheidende Faktoren sein.
Die Suche und die Navgiation wird definitiv nicht nur über eine Suchgmaschine stattfinden und gerade im Feld der Sprachsuche ist Amazons Alexa ein ernst zunehmender Gegner für die Suchmaschine Google. Zudem beruht das Geschäftsmodell von Amazon, nicht wie bei Google, das auf Werbeeinnahmen. Dieses entscheidende Umstand veranlasst mich dieser zu der Annahme, dass Amazon hier die bessere Ausgangslage und den längeren Atem haben wird. Da hier eine nachhaltige Finanzierung der Entwicklung von neuen Technologien gewährleistet ist. Schon jetzt verlagern Onlinmarketer immer größere Werbebudgets in Richtung Amazon, was für Amazon aber nur eine zusätzliche Einnahmequelle ist, für Google aber alles bedeutet.
Quellen:
- https://developer.amazon.com/de/blogs/alexa/post/352e9834-0a98-4868-8d94-c2746b794ce9/improve-alexa-skill-discovery-and-name-free-use-of-your-skill-with-canfulfillintentrequest-beta
- https://developer.amazon.com/de/blogs/alexa/post/4e6db03f-6048-4b62-ba4b-6544da9ac440/the-scalable-neural-architecture-behind-alexa-s-ability-to-arbitrate-skills
- https://developer.amazon.com/de/blogs/alexa/post/c870fd31-4f91-4a62-a137-8dfa70ca5e9c/hyprank-how-alexa-determines-what-skill-can-best-meet-a-customer-s-need
- https://developer.amazon.com/de/blogs/alexa/post/84e34d41-4ab5-4080-8924-6ebb8eb8c5e1/distributed-re-ranker-ensures-that-alexa-improvements-reach-customers-asap
- https://www.faz.net/aktuell/wirtschaft/diginomics/unternehmen-investieren-werbebudget-vermehrt-bei-amazon-15796306.html